第一次出问题
想在kibana查看new-word的日志,发现没有一点日志,然后使用node ip去查询,发现10个节点中,只有2个日志是正常的。
kubectl get pods -n kube-system -o wide|grep fluentd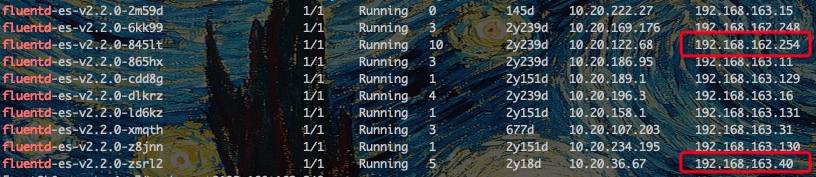
两种可能:
es 负载过高(es目前有2个节点,主节点在new-elk,CPU负载在100%上下徘徊)
fluented-es组件有bug:https://github.com/uken/fluent-plugin-elasticsearch/issues/742
可通过 kubectl describe cm -n kube-system fluentd-es-config-v0.1.5 获取 fluentd 的配置,里边的overflow_action是block,加上内存基本达到pod的限制(fluent会把日志切成chunk,目前是2M,堆积在内存并在硬盘备份),大概率还是ES的瓶颈问题。
参考:https://docs.fluentbit.io/manual/administration/buffering-and-storage
注意如果以后恢复,目前是tail规则,但要清理pos_file(存放日志文件读取进度)
第二次出问题
一点日志也没有了,最近的日志是22年11月,正好和kibana的升级日期很接近。
然后查看了以前正常运行的两个fluentd节点日志:
2023-02-27 08:58:55 +0000 [warn]: failed to flush the buffer. retry_time=858402 next_retry_seconds=2023-02-27 08:59:27 +0000 chunk="5e79a01d4890ac29a31c49121b1cf9cf" error_class=Elasticsearch::Transport::Transport::Errors::BadRequest error="[400] {\"error\":{\"root_cause\":[{\"type\":\"illegal_argument_exception\",\"reason\":\"Action/metadata line [1] contains an unknown parameter [_type]\"}],\"type\":\"illegal_argument_exception\",\"reason\":\"Action/metadata line [1] contains an unknown parameter [_type]\"},\"status\":400}"
2023-02-27 08:58:55 +0000 [warn]: suppressed same stacktrace查到两个相关的解决方式: - 通过fluent-plugin-elasticsearch 的issue猜测是升级elasticsearch到8.x出现的问题,移除了一个参数。 - 而 fluentd-kubernetes-daemonset 的issue则是增加了一块配置
看了一下我们使用的image是个5年前的包,而且不是fluent官方包。
看我们自己正在使用的image信息,最后一行是CMD ["/bin/bash" "/usr/local/bin/kibana-docker"] ,还看不出来fluent 相关的东西。
接下来打算尝试升级一下image,替换成最新的官方包。
顺便看一下elasticsearch从7升级到8的官方文档,是否有修改数据传输格式。
未完待续…