在上传一个368M的zip包时,会有tengine的一个entityTooLarge的报错
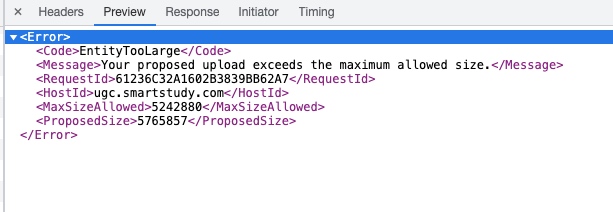 调整了nginx的配置:
调整了nginx的配置:
client_max_body_size 1024m;
client_body_timeout 1800s;还是报同样的错。 碰巧看到CDN的300M上传限制,想到域名用了 DCDN 全站加速,于是提了工单,确认了 DCDN 也有300M的限制。另外配置了不加速的域名,解决了entityTooLarge的问题。
继续上传zip包,4分钟左右,报504或者502. ngingx又加了配置:
proxy_connect_timeout 1800s;
proxy_send_timeout 1800s;
proxy_read_timeout 1800s;仍然是响应超时,遂登到k8s,看到当前项目的deployment,同一replica,有很多状态是 Evicted 的 Pod。使用 Describe 命令查看,Message字段显示的是 DiskPressure,找到相关的文档:配置资源不足时的处理方式。向杨鹏求助,建议我查看kubelet配置的nodefs.available, nodefs.inodesFree, imagefs.available, 或 imagefs.inodesFree。权限不够,暂时没去看。
Running状态的pod发现有重启次数,怀疑有crash情况,遂查看崩溃前container的日志:
kubectl logs pod-7d8b49557c-c2lx9 --previous发现有下图的情况:
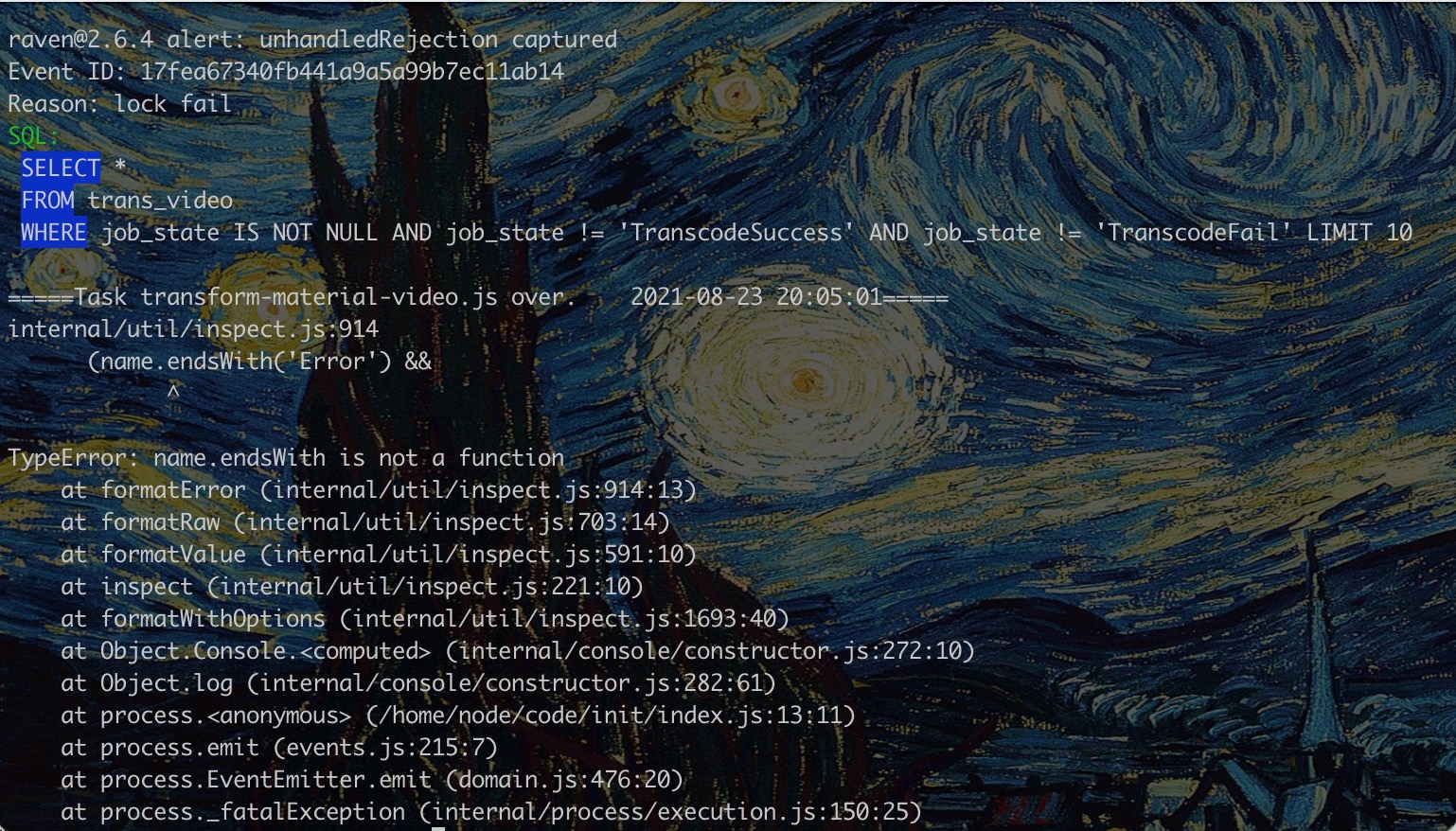
最后两条线都没跟下来,时间略紧迫,放弃了zip包上传,改为文件夹批量上传。